Prioritize data broker removals when one record spreads
Learn how to prioritize data broker removals by tracing which record feeds others, so you can remove high-spread sources before copy sites.
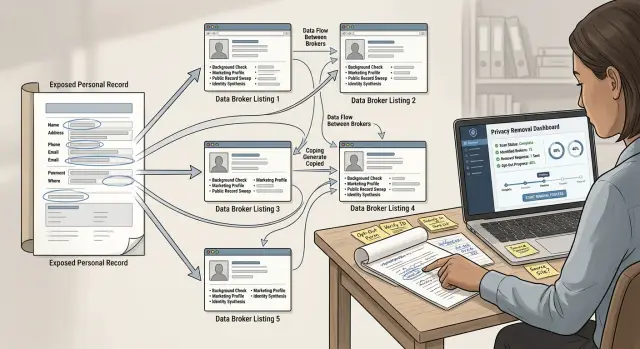
Why one exposed record can spread so fast
When you look up your information on people-search sites, the first profile you find is often not the first one that existed. It may simply be the page that ranks well in search, updates more often, or gets copied more widely.
That matters because data brokers copy from each other all the time. One broker collects a name, old address, phone number, age range, or relatives list. Another broker buys, scrapes, licenses, or syncs that record into its own database. A third site picks it up later. Before long, one exposed profile turns into five or ten, with small differences that make them look unrelated.
Search results can make this worse. The site on page one may be easy for search engines to crawl, while the quieter source barely appears at all. If you remove the loudest result first, the original source can keep feeding the same details back into the network.
The cost is usually time. You fill out opt-out forms, verify your identity, wait for confirmation, and then see the same details come back under a fresh page or a slightly different profile. That feels random. Most of the time, it isn't. The source was never removed.
Picture a simple case. One broker posts your mobile number with an old home address. Four other sites import that record. You spend an hour removing the four copies because those are the ones you found first. If the source stays live, the next sync can recreate the copies and put you right back where you started.
That is why chain-based thinking works better than panic cleanup. Instead of chasing every visible result, ask a better question: which record is feeding the rest?
How to spot the source and the copies
A loud search result is not always the source. Many broker pages are copies of an older, fuller record that has already spread. To sort them, compare what each site shows rather than how high it ranks.
The first clue is detail level. A source page often has the fullest profile: full name, age, past addresses, relatives, phone numbers, and sometimes old email history. Copy pages are usually thinner. They may show only part of an address, one phone number, or a short profile that looks trimmed down.
Next, compare several listings side by side. Look for exact matches, not just similar facts. If three smaller sites use the same middle initial, the same old address format, and the same misspelled street name, they probably pulled from the same record. Independent records usually differ a little. Copies often repeat odd details exactly.
Wording matters too. Many smaller sites reuse the same labels, phrasing, and order of information. If you keep seeing the same section names, the same wording around relatives, or the same layout of cities and ages, that is usually a reuse pattern, not a coincidence.
A quick way to sort pages is to ask four questions:
- Which site has the fullest profile?
- Which details match word for word?
- Which errors or stale facts repeat?
- Which pages look stripped down or templated?
For example, one site lists "Jonathan A. Reed," three past addresses, two relatives, and a landline from 2018. Five other sites show the same middle initial, the same old landline, and the same second address written in the same odd format. The fuller record is probably the source. The other five are likely copies.
This is the difference between a cleanup that sticks and one that keeps repeating. Remove the source, and fresh copies are less likely to appear. Remove only the copies, and the same record can show up again a week or two later.
Make a simple spread map first
Before you send a single opt-out request, make a plain spread map. You do not need special software. A notes app, spreadsheet, or sheet of paper is enough.
The goal is simple: stop guessing which site matters most. If the same person shows up on eight sites, those pages are rarely equal. One or two often feed the rest.
Start by writing down every site where the record appears. Next to each site, note exactly what is exposed: home address, phone number, age or birth year, relatives, old addresses, or email. Keep it short and specific.
Then look for patterns. If three sites show the same phone number, the same age, and the same relative in the same order, they are probably connected. Group those together. If another site has older facts, a missing apartment number, or a different phone, put it in a separate group.
This is where the map becomes useful. The page with the fullest profile is often the source, especially if smaller sites repeat its wording or unusual details. A page that lists your current address, two past cities, a landline, and three relatives has more spread power than a thin page with only a name and city.
A simple table works well:
| Site | Data shown | Matching group | Likely source? |
|---|---|---|---|
| Site A | Address, phone, relatives | Group 1 | Yes |
| Site B | Address, phone | Group 1 | Maybe copy |
| Site C | Old address only | Group 2 | No |
Once you can see the groups, circle the site that seems to feed the others. That is usually where you start.
What to remove first
Start with the record that gets copied the most. If one broker seems to feed five or six smaller sites, that source should usually go first. Cutting off the source often reduces how many copied records you have to clean up later.
Do not assume the loudest result deserves first place. A listing on page one of search results can feel urgent, but a quieter broker may be the one other sites keep scraping. Spread matters more than noise.
Then add a risk filter. Move any record up the list if it shows your home address, personal phone number, or details that make contact easy. A record copied by three sites can deserve faster action than one copied by five if it exposes where you live.
Large brokers usually come before one-off mirror pages. Big people-search sites are copied often, and their records tend to stay in circulation longer. Small copies still matter, but many of them dry up after the main source is removed.
A practical order looks like this:
- Remove the source that appears to feed the most other listings.
- Move address and phone exposure higher, even if it spreads less.
- Clear larger brokers before spending time on isolated copy pages.
- Leave low-traffic copies for later when they seem to depend on a source you already targeted.
Say one site shows your full address and is copied by four others, while another ranks higher in search but lists only your age and an old city. The first site is the better first move because it has both higher spread and higher risk.
A practical way to set priorities
Do not think page by page. Think in chains.
Start with a focused search. Look up your full name with one detail at a time: current city, phone number, and an old address if you have one. That usually surfaces records that are close enough to compare without flooding you with unrelated results.
Open only a small batch first, around five to ten matching records. You are not trying to clear the whole internet in one sitting. You are trying to spot patterns.
Work through them in a simple order. Compare the details on each record. Note what repeats exactly, including spelling, age range, relatives, and address history. Mark which sites show the most complete version. Then check which pages seem to update most often.
If three sites have the same old phone number, the same middle initial, and the same misspelled street name, they probably came from the same upstream source. That source matters more than the copy that ranks highest in search.
After that, score each site on three things:
- Spread: does this site seem to feed many others?
- Sensitivity: does it expose your current address, mobile number, or family links?
- Update speed: if removed today, how quickly is it likely to come back or republish elsewhere?
A simple rule works well. High spread and high sensitivity goes first. High spread with lower sensitivity still belongs near the top. Low spread but high sensitivity should not wait long. Old partial records with little reach can come later.
Then send removal requests in that order and track the date for each one. A plain sheet is enough. Note the site name, record details, request date, response, and a recheck date 7 to 14 days later. That follow-up matters because copied records often disappear only after the source is gone.
A realistic example of chain-based removal
Say Jordan searches his name and finds one people-search page with his full street address, age, relatives, and a mobile number he still uses. On the same day, he finds three smaller sites with thinner profiles.
Those smaller pages repeat the same phone number, city, and one past address, but they do not show much else. That pattern is the clue. The larger people-search site is probably feeding the smaller sites, or all of them buy from the same upstream source.
Either way, the page with the most detail is doing the most damage. That is the first one to remove.
Jordan maps it like this:
- Site A: full profile, current address, past addresses, relatives, phone
- Site B: phone, city, age range
- Site C: phone, past address
- Site D: phone, relatives, city
If Jordan sends requests to all four sites right away, he may still have to do the same work again. Smaller sites often refresh their records after a few days or weeks. If the larger source is still live, the copied listings can come back.
A better move is to remove Site A first and then recheck the others. Once the main source goes dark, some smaller pages disappear on their own. Others stay up, but the record gets thinner, which makes follow-up requests easier.
A week later, Jordan checks again. Site B has dropped the phone number. Site C now shows only his name and city. Site D is still live, so he sends one more removal request there.
That is far less repeat work. He handled one major source and one stubborn copy instead of chasing four sites in circles.
Mistakes that waste time
The biggest time sink is chasing the first search result you see. It feels urgent because it is public and easy to find. But the page ranking first is often a copy, not the source.
Another common mistake is treating every listing as equally serious. They are not. A profile with your full name, past addresses, age range, relatives, and phone number can connect many other records. A thin page with only a city and state usually spreads less.
Old addresses cause more trouble than many people expect. People skip them because they feel outdated. That is a mistake. An old street address can act like glue between records, especially when brokers use it to match your phone number, family members, or previous moves. Even one stale address can keep copied profiles alive.
A quieter problem is failing to save proof before a page changes. Broker pages update fast. A record may lose a phone number, gain a new relative, or disappear right after an opt-out request. If you did not save the original page, it gets much harder to trace where the copied records came from.
Before you send anything, save:
- a full-page screenshot
- the broker name and page title
- the exact fields shown, such as address, age, phone, or relatives
- the date you found it
That takes a minute, and it can save hours later.
Before you send requests
Do the prep work first. It is not exciting, but it keeps you from sending the wrong request to the wrong site.
A copied record can look almost identical across several brokers, yet one small detail often changes. A middle initial appears on one page. A city is shortened on another. If you do not save those details up front, it gets harder to match the source page to the copies later.
Keep a short checklist for each request. Save a screenshot and the date. Write down the exact name, city, and other details shown on the page. Note where the request must go, whether that is a form, support email, or mailing address, along with any ID requirement or confirmation step. Then pick a follow-up date before you close the tab.
Wording matters more than most people expect. A site may list "John A Smith" in Phoenix, while another says "John Smith" in Glendale. That can still be the same person and the same spread chain. Good notes keep you from treating them as two separate cases.
Deadlines matter too. Some brokers send a confirmation email that expires in a day or two. Others remove the page only after you reply to a message or confirm from the same browser session. Miss that step, and the request may just sit there.
For many removals, 7 to 14 days is a practical first check. By the time you send the request, you should already know three things: what page you saw, where you sent the request, and when you will verify the result.
What to do after the first removals
The first removal is not the finish line. It is the first break in the chain.
After a broker removes your record, wait 7 to 14 days and check the copy sites again. Some sites pull fresh data on a delay, so they may not change right away. Others keep old pages live even after the source is gone.
A boring routine works better than panic searching. Pick one day each week, recheck the source you removed, then recheck the obvious copy sites that depended on it. If a copied listing is still there after the source disappears, that copy now deserves its own request.
Keep a small log as you go. A spreadsheet is enough. Track the site name, the date you sent the request, the current status, the next recheck date, and a short note on whether the page looks like a source or a copy.
This cuts down on repeat work and shows patterns quickly. If the same broker keeps putting your phone number or address back online, that site needs regular monitoring, not a one-time opt out.
Re-listings are common on brokers that republish data from fresh feeds. You may remove a record in week one and see it return a month later with a slightly different age, address format, or relatives list. When that happens, update your log and send the next request right away.
If one people-search page is gone but 10 days later two smaller sites still show the same old address, check whether they copied the page before it came down or whether they now pull from another broker. If it is stale data, a direct removal request may finish the job. If it is a new feed, you found another source worth tracking.
If you do not want to manage that process by hand, Remove.dev can automate removals across more than 500 data brokers, track each request in real time, and keep watching for re-listings. That is useful when the hard part is no longer finding one exposed record, but keeping the copies from coming back.
FAQ
What should I remove first?
Start with the record that seems to feed the most other pages, especially if it shows your current address or phone number. Removing the source first usually cuts down the repeat work later.
How can I tell which site is the source?
Compare the details, not the search ranking. A source page is often fuller and repeats odd facts that show up word for word on smaller sites, like the same old phone number, middle initial, or misspelled street name.
Should I start with the first search result I see?
Usually no. The top result is often just the easiest page to find, not the one feeding the rest of the network.
Why do my details come back after I remove them?
Because many brokers copy from each other on a delay. If the original source stays live, later syncs can create fresh copies even after you removed the pages you found first.
How many records should I compare before sending requests?
Keep the first pass small. Checking about five to ten matching records is usually enough to spot patterns without getting lost in noise.
Do old addresses really matter?
Yes. Old addresses often connect your name to phone numbers, relatives, and move history. Even stale information can keep copy pages alive.
What should I save before I submit an opt-out?
Save a full-page screenshot, the broker name, the page title, the exact details shown, and the date you found it. That gives you a clean record if the page changes or reappears later.
When should I check back after a removal request?
A first check in 7 to 14 days is a practical default. That gives sites time to process the request and gives copy pages time to refresh.
What if a copy site stays up after the source is removed?
Treat it as its own target. If the source is gone and the copy still shows your data after a recheck, send a direct removal request to that site and note it in your log.
Can I automate this instead of doing it by hand?
Yes. Remove.dev automates removals across 500+ data brokers, tracks each request in real time, and keeps watching for re-listings. Most removals finish within 7 to 14 days, and plans start at $6.67/mo with a 30-day money-back guarantee.