Cómo los datos de una filtración terminan en bases de datos de corredores
¿Te preguntas cómo los datos filtrados terminan en bases de datos de corredores? Este artículo explica la cadena desde registros robados hasta complementos, emparejamientos, reventas y relistados.
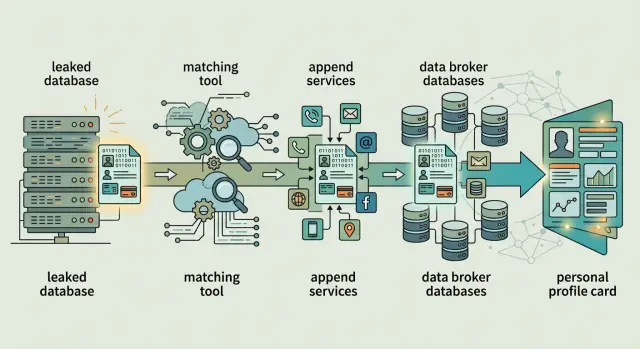
Cómo se ve esto en la práctica
La mayoría de la gente no nota esta cadena cuando ocurre la filtración. Lo nota después, cuando un número de teléfono antiguo, una dirección pasada o un correo que dejó de usar aparece en un sitio de búsqueda de personas junto a detalles actuales.
Eso es lo que hace que todo el proceso sea confuso. Los datos no se quedan en el sitio donde se filtraron primero. Se mueven. Se copian en colecciones de filtraciones, se cotejan con otros registros y se mezclan con fragmentos más recientes de otros lugares.
Un patrón común se parece a esto:
- Un sitio de compras filtra tu correo antiguo y tu dirección de casa.
- Una segunda filtración vincula ese mismo correo a un número de teléfono.
- Un corredor de datos conecta ambos con un nombre de otra fuente.
- Un detalle más reciente actualiza el perfil lo suficiente como para que parezca actual.
Las listas de los corredores resultan invasivas por una razón. A menudo no son totalmente correctas, pero son lo bastante acertadas. Un registro puede empezar como una fila medio vacía en un volcado y aun así convertirse en un perfil con tu nombre completo, rango de edad, familiares, ciudades por las que viviste y un número de teléfono que aún funciona.
Si te mudaste hace dos años y cambiaste de trabajo, una filtración antigua aún puede seguirte. Un corredor puede tomar tu dirección vieja de una filtración, tu correo personal de otra y una ciudad o empleador más reciente de otro sitio. Cuando esas piezas coinciden, el resultado parece un único registro limpio aunque provenga de varias fuentes desordenadas.
Rara vez una filtración conduce a un único problema aislado. Un solo registro filtrado puede propagarse a muchas bases de datos y luego fusionarse una y otra vez. Incluso después de que se elimina una lista, los mismos detalles pueden reaparecer cuando otro corredor reconstruye tu perfil a partir de los mismos fragmentos.
Rastrearlo manualmente lleva tiempo. La dificultad no es encontrar una mala lista: es lidiar con la forma en que los datos antiguos de filtraciones se siguen reutilizando, actualizando y vendiendo como si fueran nuevos.
Qué suele haber dentro de un volcado de filtración
La mayoría de los volcados de filtraciones parecen menos dramáticos de lo que la gente espera. A menudo son solo filas de una tabla de inicio de sesión, una base de datos de clientes o una hoja de cálculo exportada, con cada fila ligada a una cuenta.
Lo que importa es el contexto. Incluso un registro sencillo puede dar a alguien un punto de partida sólido. Los campos más comunes son direcciones de correo, nombres de usuario y hashes de contraseña. Un hash de contraseña es una versión encriptada de una contraseña. Normalmente no se lee como texto normal, pero sigue ayudando a conectar cuentas provenientes de la misma filtración. En algunos casos, también puede ayudar a comprobar si alguien reutilizó la misma contraseña en otro sitio.
Algunos volcados incluyen más. Pueden tener nombre completo, número de teléfono, fecha de nacimiento, dirección postal, dirección IP o respuestas a preguntas de recuperación. Las filtraciones antiguas de consumidores suelen traer datos de envío, datos de facturación o textos de perfil que la gente olvidó que había puesto.
Las fechas importan más de lo que parece. Una fecha de creación de cuenta, la última conexión, la fecha de compra o el reinicio de contraseña ayudan a situar el registro en el tiempo. Eso facilita compararlo con otros registros y decidir si dos cuentas probablemente pertenecen a la misma persona.
Los identificadores de cuenta parecen aburridos hasta que ves lo que hacen. Un número de cliente, ID de usuario, ID de pedido o ID de fidelidad puede ligar un registro a un servicio y a un periodo concreto. Ese contexto extra hace que el emparejamiento posterior sea mucho más fácil.
Un ejemplo pequeño lo deja claro. Una filtración de un sitio de compras puede incluir un correo, un nombre de usuario, un hash de contraseña, un teléfono, una dirección de apartamento de 2021, un ID de cliente y la fecha del último pedido. Ningún campo por sí solo prueba mucho. Juntos, apuntan a una persona real.
Los datos antiguos siguen teniendo peso. La gente mantiene cuentas de correo durante años, reutiliza números de teléfono y deja rastros de direcciones antiguas en formularios de registro, registros de entrega y archivos públicos. Incluso los datos obsoletos pueden ayudar a emparejar cuando otra base de datos completa las piezas faltantes.
Cómo un registro filtrado se asocia a una persona
La mayoría de los emparejamientos arrancan con un campo que viaja bien por internet: la dirección de correo. La gente reutiliza el mismo correo para compras, aplicaciones, boletines y foros antiguos. Una vez que esa dirección aparece en un volcado, se convierte en un ancla para emparejar.
Un correo por sí solo no siempre cuenta toda la historia. La confianza aumenta cuando el mismo registro también incluye un nombre, ciudad, código postal o rango de edad. Incluso detalles aproximados pueden ser suficientes. Si un archivo dice A. Johnson en Denver, 45-54 años, y otro tiene el mismo correo más un nombre de pila completo, un corredor puede tratarlos como la misma persona.
Los datos viejos siguen teniendo poder de emparejamiento. Un número que dejaste de usar, una dirección postal de años atrás o un nombre de usuario de una cuenta olvidada pueden conectarte cuando coinciden con archivos más recientes. La gente suele asumir que los datos obsoletos son inofensivos. En la práctica, pueden actuar como un puente entre un registro filtrado y una identidad actual.
El proceso de emparejamiento suele basarse en la probabilidad, no en la perfección. Un corredor no necesita que todos los campos estén correctos. Si cuatro detalles coinciden y uno está equivocado, el registro puede quedarse en la base de datos. Por eso a veces ves listados con una ciudad antigua, un nombre mal escrito o un familiar vinculado a la dirección equivocada. El registro es defectuoso, pero lo bastante cercano para conservarlo.
Piensa en un ejemplo sencillo. Una filtración de un minorista incluye un correo, un nombre parcial y una dirección de envío de 2019. Un segundo archivo de un proveedor de marketing tiene ese mismo correo y una ciudad más reciente. Una tercera fuente añade una banda de edad. Ninguno de esos archivos es completo por sí mismo, pero juntos pueden apuntar a una persona con una puntuación bastante alta.
Esto también explica por qué la eliminación de datos personales exige más que borrar un listado. Si la misma persona se empareja a partir de varios registros antiguos, pueden aparecer nuevos listados incluso después de eliminar una versión. Los datos pueden ser desordenados, pero la coincidencia puede quedarse.
Dónde encajan los servicios de append y las herramientas de enriquecimiento
Un volcado de filtración rara vez empieza como un perfil completo. Más a menudo es un registro fino: una dirección de correo, una contraseña antigua, quizá un nombre, quizá nada más.
Los servicios de append rellenan los vacíos. Si un archivo tiene un identificador sólido, intentan adjuntar un número de teléfono, dirección, rango de edad u otros detalles de contacto. Piensa en un correo filtrado de una cuenta de compras. Por sí solo, tiene limitaciones. Si ese mismo correo aparece en una lista de marketing, un registro de garantía y una base de datos de búsqueda de personas, un servicio de append puede conectar esos puntos y añadir campos faltantes.
Las herramientas de enriquecimiento van más allá. En lugar de completar una casilla, tiran de fuentes públicas y comerciales para hacer el registro más útil. Eso puede significar familiares probables, direcciones anteriores, puesto de trabajo, datos del hogar o un segundo número de teléfono.
El emparejamiento no tiene que ser perfecto desde el primer intento. Las pequeñas superposiciones a menudo hacen el trabajo. Un archivo coincide por correo. Otro por número de teléfono. Un tercero por código postal y año de nacimiento. Tomados por separado, cada emparejamiento parece débil. Juntos, bastan para conectar varios registros a una persona.
Por eso una lista de corredor puede parecer más completa que la filtración original. La brecha puede haber expuesto solo un dato sobre ti. Los servicios de append y las herramientas de enriquecimiento añaden el resto extrayendo fragmentos que ya existían en otros lugares.
Un ejemplo simple lo deja claro. Supón que una filtración expone [email protected] y una ciudad antigua. Una base de datos aparte tiene ese correo con un número de móvil. Otro archivo tiene ese mismo número ligado a una dirección actual. Un corredor puede fusionar esas piezas y acabar con un perfil que parece actual aunque ninguna fuente tuviera toda la información.
Cómo los corredores convierten fragmentos en un perfil
Un corredor normalmente no empieza con un archivo limpio y completo sobre una persona. Empieza con migas. Una filtración puede tener un correo y un hash de contraseña. Otro archivo puede tener un teléfono, una dirección antigua o un año de nacimiento. Una fuente de datos de compras puede añadir rango de ingresos o suposiciones sobre la propiedad de la vivienda. Por sí solas, esas piezas parecen débiles. Juntas, pueden apuntar a una persona o a un hogar.
El siguiente paso es agrupar. El corredor empareja registros que parecen pertenecer juntos y luego los integra en un solo perfil. Si el mismo correo aparece junto al mismo teléfono en dos sitios, el emparejamiento se fortalece. Si una dirección antigua conecta con una dirección nueva mediante un registro de reenvío, el perfil crece.
Muchos corredores usan puntuaciones en segundo plano. No tratan cada coincidencia como igual de sólida. Los detalles que es menos probable que se compartan o a los que la gente suele equivocarse reciben más peso. Una dirección de correo repetida importa más que una banda de edad vaga. Un número de teléfono ligado a dos direcciones puede pesar más que una estimación de ingresos.
Una vez que la puntuación supera el umbral del corredor, el registro puede publicarse, venderse o pasarse a otro vendedor. Ahí es donde la cadena se vuelve desordenada. Un corredor puede comprar un perfil, añadir algunos detalles y revenderlo a otros corredores, vendedores de leads o sitios de búsqueda de personas. El siguiente comprador puede tratar ese perfil como una fuente nueva aunque la coincidencia original solo fuera parcialmente correcta.
Este reciclaje es por qué los datos eliminados pueden volver. Una lista baja, luego llega un nuevo archivo con el mismo correo, teléfono o dirección. El corredor lo empareja de nuevo, reconstruye el perfil y lo vuelve a publicar parcialmente.
Para la gente normal esto parece aleatorio. No lo es. Es una cadena de pequeñas suposiciones reutilizadas una y otra vez. Por eso la eliminación suele ser continua, no de una sola vez.
Un ejemplo sencillo desde la filtración hasta la lista del corredor
Esta cadena a menudo empieza con algo pequeño y antiguo, no con un archivo de identidad completo.
Digamos que una tienda de ropa sufre una filtración. El registro filtrado tiene la dirección de Gmail antigua de Maya, su código postal y la fecha en que se suscribió a alertas de ofertas. Eso no parece suficiente para crear una página de búsqueda de personas, pero sí basta para empezar a emparejar.
Un servicio de emparejamiento comprueba ese correo contra otras bases de datos. Encuentra la misma dirección en un registro de programa de fidelidad de otro minorista, donde Maya usó su nombre y apellido reales. Ahora el registro filtrado ya no es solo correo antiguo más código postal: está ligado a una persona.
A continuación, un servicio de append rellena los vacíos. El proveedor conecta ese registro emparejado con un número de móvil y una dirección de calle extraídos de datos de envíos anteriores, tarjetas de garantía u otros archivos de marketing. Ninguna de esas fuentes tiene que ser perfecta por sí sola. Solo necesitan suficiente superposición para aumentar la confianza.
Una vez que un corredor compra o recibe ese registro combinado, puede añadir etiquetas más amplias. A Maya la pueden ubicar en un rango de edad, tamaño probable del hogar y una suposición sobre si es propietaria, según otros archivos que el corredor ya tenga. Esas deducciones pueden ser parciales, pero hacen que el perfil parezca completo.
Pronto, un sitio de búsqueda de personas tiene suficiente para publicar una lista. Puede mostrar el nombre de Maya, dirección actual o pasada, banda de edad, número de teléfono y posibles familiares. La filtración original no contenía todo eso. El resto vino del emparejamiento, el append y el enriquecimiento con el tiempo.
Cada paso puede parecer ordinario por separado: un correo filtrado aquí, un registro de fidelidad allá, un número de teléfono agregado después. Juntos, convierten un registro fino en algo que se siente invasivo.
Cómo trazar la cadena paso a paso
Cuando la gente intenta averiguar de dónde vino una lista de corredor, a menudo abre demasiadas pestañas y pierde el hilo. Un método más pequeño funciona mejor. Empieza con un correo y un número de teléfono.
Elige el par que hayas usado durante más tiempo, aunque uno de ellos sea antiguo. Un nombre completo puede crear ruido. Un correo y un teléfono suelen dar coincidencias más limpias.
Luego busca repeticiones. Si el mismo correo aparece en varias páginas de corredores, registros de cuentas antiguas o alertas de filtraciones, anótalo. Si el teléfono aparece con dos direcciones diferentes, guarda ambas. Los corredores a menudo construyen un perfil reutilizando detalles que siguen apareciendo en distintos sitios.
La señal más reveladora es una mezcla de información antigua y actual. Si una lista tiene tu número móvil actual, una dirección de 2018 y un correo que dejaste de usar el año pasado, eso suele indicar que el registro se fue actualizando con el tiempo. No apareció completo: partes se añadieron después mediante servicios de append o fuentes de enriquecimiento.
Las fechas te ayudan a adivinar el orden. Una filtración de 2021, una lista de búsqueda de personas vista por primera vez en 2023 y una dirección más reciente añadida en 2024 pueden sugerir una cadena probable. Puede que no pruebes cada traspaso, pero a menudo puedes ver cuándo se actualizó el registro.
Una nota simple funciona mejor que una hoja de cálculo complicada:
- Escribe un correo y un teléfono.
- Marca cada lista donde aparecen juntos.
- Señala detalles que están desactualizados frente a los actuales.
- Añade la fecha en que encontraste cada página.
- Guarda una captura de pantalla antes de enviar cualquier petición de eliminación.
Ese último paso importa. Las páginas de los corredores cambian rápido. Un registro puede desaparecer y luego volver con una banda de edad nueva o una ortografía ligeramente distinta. Si comparas versiones después, las capturas facilitan detectar relistados.
No necesitas un mapa perfecto. Solo necesitas evidencia suficiente para ver el patrón. Cuando el mismo correo, teléfono y dirección antigua siguen reapareciendo juntos, la cadena se vuelve más legible.
Errores comunes al juzgar tu exposición
La mayoría de la gente valora su riesgo por la última filtración de la que oyó hablar. Eso es un atajo malo.
Cambiar la contraseña ayuda con el acceso a la cuenta. No recupera los datos que ya se copiaron y siguen circulando. Tu nombre, correo, teléfono, dirección antigua o fecha de nacimiento pueden seguir moviéndose mediante listas de reventa mucho después de la filtración original.
Otro error es fijarse solo en la compañía que fue hackeada. Eso te dice dónde empezó la fuga, no adónde fue después. Un registro filtrado puede venderse, cotejarse con otros archivos y luego rellenarse mediante servicios de append y enriquecimiento. Cuando llega a un perfil de corredor, puede incluir detalles que la compañía afectada nunca tuvo.
Los detalles antiguos importan más de lo que se piensa. Una dirección de hace seis años puede seguir ayudando a conectarte con una lista actual. Lo mismo ocurre con un número antiguo, un empleador anterior o un correo que casi no usas ahora.
La gente también subestima su exposición buscando solo con datos actuales. Buscan su ciudad y correo actuales, encuentran poco y asumen que están bien. Mientras tanto, un corredor puede estar usando una dirección antigua como registro ancla y agregando detalles más recientes alrededor.
Un tercer error es tratar una eliminación como una solución total. Que un registro de un corredor se borre no significa que el problema desapareció. Los datos se copian, revenden y reconstruyen. Una lista eliminada hoy puede reaparecer si otro corredor aún conserva la misma fuente.
Una mejor forma de valorar la exposición es buscar patrones: direcciones pasadas, correos antiguos o alternativos, variaciones del nombre, vínculos familiares, miembros del hogar y listados repetidos en varios corredores. Esa exposición repetida es lo que más importa. La eliminación funciona mejor cuando es continua, no única.
Comprobaciones rápidas y pasos siguientes
Una vez que entiendes cómo funciona esta cadena, el primer trabajo es simple: junta tus datos en un solo sitio. La mayoría de la gente lo hace de memoria y se pierde la mitad. Correos antiguos, un segundo número de teléfono o un piso anterior pueden ser suficientes para emparejarte con un perfil mucho más grande.
Haz una lista corta con los correos que sigues usando y los antiguos que pueden aparecer en volcados, todos los números móviles o fijos que has usado, direcciones de domicilio pasadas, variaciones comunes de tu nombre y las páginas de corredores que más te exponen. Prioriza primero las páginas que muestran una dirección de casa, familiares o fecha de nacimiento.
Esa lista te da algo concreto contra lo que comprobar las páginas de corredores y las alertas de filtraciones. Si un correo antiguo sigue apareciendo una y otra vez, es una pista. Si una página de corredor incluye tu dirección actual y familiares, súbela en la lista de limpiezas.
Mantén el seguimiento simple. Una nota con el nombre del corredor, fecha de la solicitud y fecha de la comprobación es suficiente. Lo que importa es ver patrones: qué sitios eliminan rápido y cuáles vuelven a publicar silenciosamente un mes después.
Un ejemplo pequeño ayuda. Supón que una cuenta de compras antigua filtró tu correo, teléfono y ciudad. Más tarde, un corredor empareja ese correo con un registro de cambio de dirección y añade tu dirección actual. Otro corredor copia ese perfil. Ahora tienes dos listados que eliminar, no uno.
Las exclusiones manuales pueden funcionar, pero resultan agotadoras cuando lidias con muchos registros y comprobaciones repetidas. Si no quieres gestionar docenas de formularios, Remove.dev automatiza eliminaciones en más de 500 corredores, vigila relistados y te permite seguir las solicitudes en un solo panel.
El mejor siguiente paso no es una investigación perfecta. Es una lista corta, unas cuantas eliminaciones de alto riesgo primero y revisiones regulares.